Natural Language Processing mit Python
In einer Reihe von Blogposts wollen wir uns einem spannenden Thema, nämlich “Natural Language Processing” (NLP), also der computergestützten Verarbeitung von Sprache widmen. Die einzelnen Blogposts der Series bauen dabei lose aufeinander auf und zeigen typische Schritte eines NLP-Workflows. Das Ziel der Serie ist zum einen, dass Du einen Eindruck der einzelnen Schritte der Datenbeschaffung, -vorverarbeitung, und tatsächlichen konkreten Uses Cases für NLP gewinnst und zum anderen, dass Du die Benutzung populärer Python-Libraries, die sich für NLP Workflows gut eignen, kennenlernst.
In diesem ersten Teil zeigen wir zunächst wie man sich eine Datenbasis von Texten aus Zeitungsartikeln beschaffen kann und thematisiert deswegen das Thema “Web Scraping mit Scrapy”.
In einem zweiten Teil werden wir dann zeigen wie man Sprachdaten in Textform vorverarbeiten kann um sie für verschiedene Use Cases aufzubereiten. Dort werden wir uns mit Themen wie Tokenization, Stop-words, Stemming (d.h. Wortstämmen) und Normalisierung beschäftigen.
In den darauf folgenden Teilen wird es dann noch einmal ein Stück spannender: Wir wollen uns darin jeweils mit verschiedenen Use Cases, wie z.B. Textclassification, Sentiment-Analysis, oder Recommendation auseinandersetzen.
Teil 1: Web Scraping mit Scrapy
Einführung
Zwar existiert bereits eine Reihe vorgefertigter Textsammlungen, anhand derer man sich mit NLP auseinandersetzen kann. Allerdings haben wir uns für diesen Blog aus zwei Gründen gegen die Nutzung einer solchen Sammlung entschieden: Zum einen sind die Texte dieser Sammlungen meist in englischer Sprache verfasst. Zum anderen steht bei realen Projekten zunächst die Beschaffung von Daten als erster Schritt an. Deswegen finden wir es spannender und lehrreicher zu erklären, wie man sich Daten durch Scraping beschaffen kann. Den Scraper, den wir hier in Ausschnitten beschreiben entwickelten wir für einen Kunden (eine Tageszeitung) im Rahmen eines Proof of concepts für einen Recommender Algorithmus.Die Grundprinzipien dieses Web Scrapers wollen wir hier beschreiben.
Web Crawler kennt man für gewöhnlich im Zusammenhang mit Suchmaschinen wie Google oder Bing, die diese zur Indexierung von Internetseiten verwenden, um später bei Suchanfragen möglichst schnell passende Webseiten identifizieren zu können. Dazu “krabbeln” (engl. crawl) die Web Crawler, u.a. über Verlinkungen von einer Webseite zur nächsten, analysieren deren Inhalt, und vermerken ihn in einem Index (bzw. genauer Inverted-Index). Dasselbe Prinzip kann aber auch für das Web Scraping, d.h. die Extraktion von Informationen benutzt werden. Hierbei werden gezielt spezielle Inhalte von Webseiten ausgelesen, in unserem konkreten Fall die Volltexte aktueller Zeitungsartikel einer Tageszeitung.
Zunächst stellt sich eine wichtige Frage: Sind Web Scraper in Deutschland überhaupt legal? Wir können hierauf natürlich keine end- und rechtsgültige Antwort geben. Laut dem bekannten Rechtsanwalt für IT- und Internetrecht Christian Solmecke kann Web Scraping prinzipiell legal sein, sofern die Websites rechtlich und technisch frei zugänglich sind und es in den AGB nicht verboten wird (siehe www.wbs-law.de). Deshalb empfehlen wir jedem der mit dem Gedanken spielt Inhalte einer Website zu scrapen im vornehinein einen genauen Blick in die AGB des jeweiligen Anbieters zu werfen.
Außerdem sollte man zusätzlich ein gesundes Maß an Menschenverstand benutzen und die Anzahl der Aufrufe pro Sekunde begrenzen um z.B. die Website des Anbieters nicht mit zu vielen Anfragen zu überfluten. Falls die Website eine dedizierte API anbietet (wie z.B. Twitter) empfiehlt es sich natürlich diese auch zu benutzen.
Für Websites gibt es seitens des Anbieters zusätzlich die Möglichkeit über die robots.txt bzw. die Metadaten den Zugriff auf bestimmte Inhalte auszuschließen. An diese Informationen sollte man sich in jedem Fall halten, wenn man einen Web Scraper benutzt. Die von uns verwendete Library Scrapy hält sich standardmäßig an diese Angaben und bietet außerdem eine AutoThrottle genannte Funktion, mit der die Last auf der besuchten Webseite reduziert werden kann.In diesem Projekt haben wir uns außerdem explizit die Erlaubnis der Tageszeitung eingeholt.
Web Scraping mit Scrapy
Für die Entwicklung unseres Web Scrapers haben wir uns für die Benutzung von Scrapy entschieden. Bei Scrapy handelt es sich um ein Open-Source Projekt, das eines der beliebtesten und mächtigsten Frameworks in Python ist um Web Scraper zu entwickeln. Scrapy macht es relativ einfach die gewünschten Daten aus einer Webseite zu extrahieren, wenn man mit der Referenzierung von Elementen über CSS oder XPath vertraut ist.
Grundsätzlich müssen beim Web Scraping zwei Aufgaben erfüllt werden: Zum einen muss man festlegen wie relevante Seiten gefunden und durchlaufen werden. Zum anderen muss man definieren wie der Inhalt der einzelnen Seiten verarbeitet und extrahiert werden soll.
Sehen wir uns dazu zunächst die Struktur der Webseite unserer Tageszeitung an:
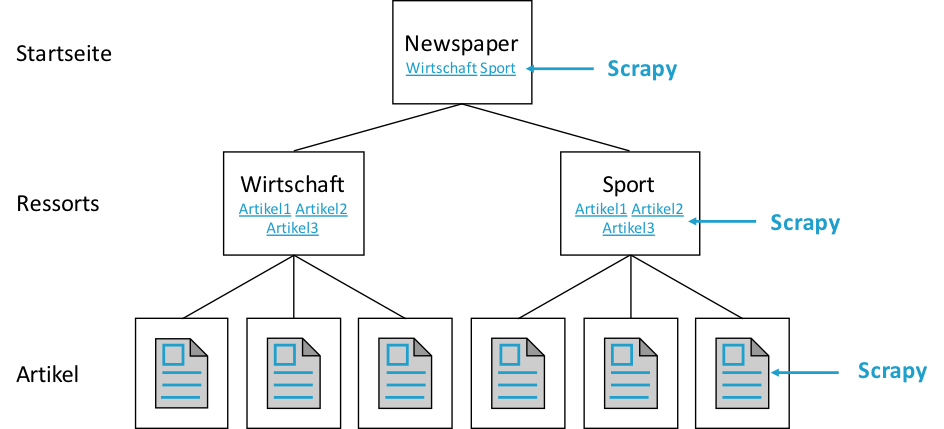
Wie wir sehen, sind die einzelnen Artikel die wir scrapen möchten in verschiedene Ressorts (wie z.B. Wirtschaft, Sport, etc.) gruppiert, die ihrerseits wiederum auf der Startseite verlinkt sind. Um nun alle Artikel zu erreichen kann dementsprechend zunächst die Startseite besucht werden um daraus die Links zu den einzelnen Ressorts zu extrahieren. Folgt man diesen Links kann man von den einzelnen Ressortseiten wiederum die Links zu den einzelnen Artikeln extrahieren und daraus dann im Anschluss die relevanten Informationen aus den jeweiligen Artikeln.
Umsetzung
Für die oben genannten Aufgaben nutzt Scrapy sogenannte Spiders. Spiders sind dabei nichts anderes als Python-Klassen mit Methoden in denen man definiert wie eine Website durchlaufen und wie Inhalte extrahiert werden sollen. Dazu schickt Scrapy, wie ein gewöhnlicher Webbrowser, einen HTTP-Request an den Server und erhält die HTTP-Response und somit den HTML-Code der Webseite in einem Python Objekt zurück. Dann bietet Scrapy die Nutzung von sowohl XPath als auch CSS-Selektoren um spezifische HTML-Elemente aus dem HTML-Code der Website zu selektieren und damit die relevanten Informationen zu extrahieren.
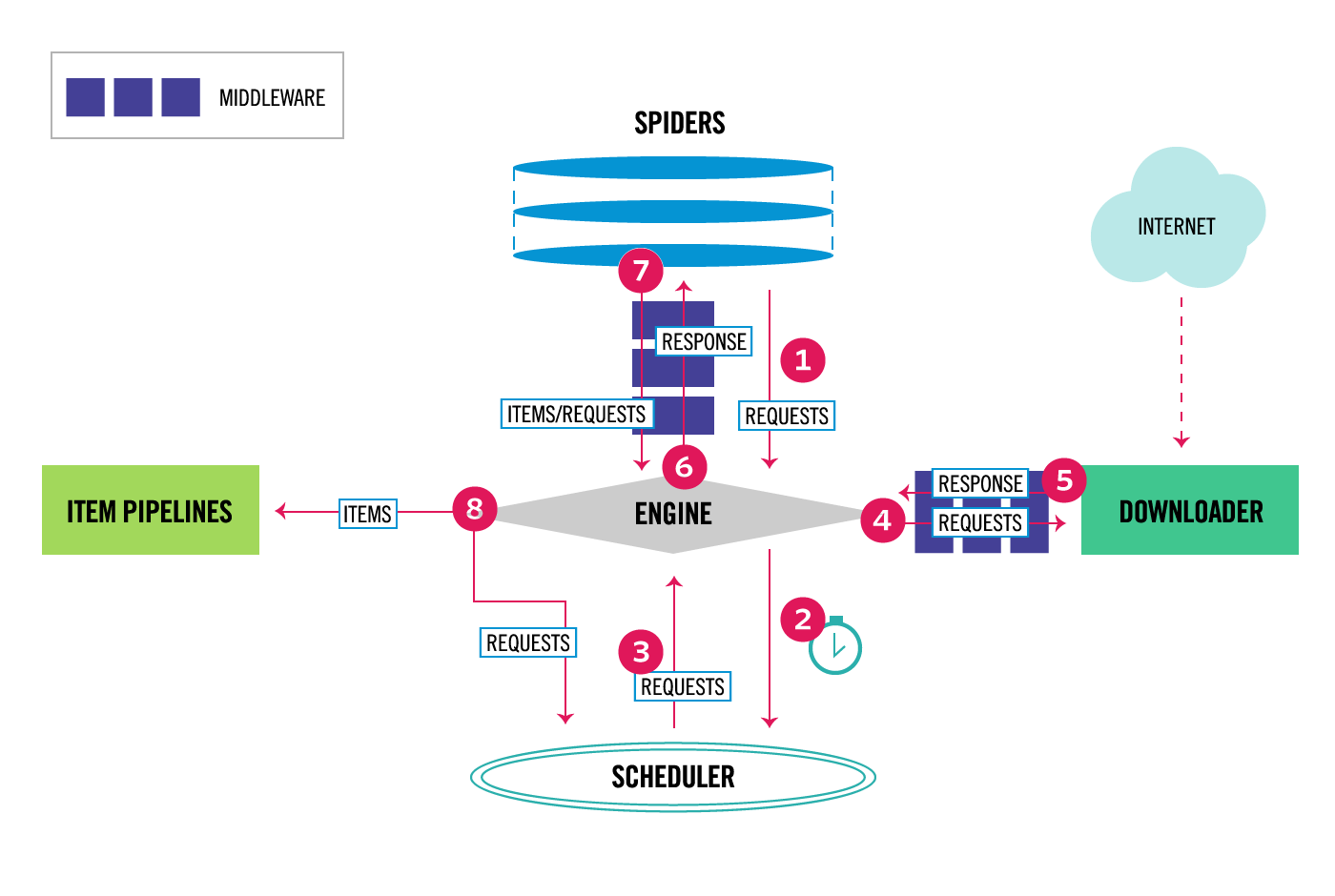
Dazu muss man als Entwickler vorher natürlich zunächst einen Blick in den Quelltext einzelner Seiten werfen um die relevanten HTML-Elemente zu identifizieren (das kann z.B. der Link zu einer Unterseite sein dem gefolgt werden soll, oder auch das Element das den Volltext eines Zeitungsartikels enthält), um entsprechende Selektoren für diese Elemente zu konstruieren. Hat man nun z.B. den relevanten Link zu einer Unterseite extrahiert, kann diese wiederum über einen HTTP-Request abgefragt werden usw. bis man auf der untersten Ebene angelangt ist. Hierbei müsste man normalerweise darauf achten keine Endlosschleifen zu erzeugen (z.B. falls sich die einzelnen Seiten gegenseitig verlinken) aber Scrapy filtert automatisch Requests an bereits besuchte Webseiten heraus.
Im Folgenden wird ein Beispielskript gezeigt das die konkrete Umsetzung in Scrapy illustriert. Der Code wurde aus Datenschutzgründen generisch angepasst. Scrapy bietet ein sehr umfangreiches Konzept (siehe auch obige Abbildung), wir beschränken uns hier aber auf die Basics.
In einem ersten Schritt definieren wir einen Spider, der auf der Klasse scrapy.Spider basiert und nennen ihnen einfach ArticleScraper. Dieser Spider benötigt in seiner einfachsten Variante zum einen die Definition der beiden Felder name und start_urls, und eine Implementierung der Methode parse.
github:b6a9b33af82d2840cd226094f7b8d5ed
Das Prinzip ist bei einem Spider folgendes: Wird ein Spider gestartet schickt er zuerst ein HTTP-Request an die in start_urls angegebenen URLs. Als Callback wird dann die Methode parse mit der HTTP-Response als Parameter aufgerufen. In der Methode parse definiert man wie die HTTP-Response weiterverarbeitet werden soll.
Wir delegieren den Aufruf weiter an unsere Methode parse_start_page, welche nun aus der Response die Ressort-URLs mit Hilfe eines CSS-Selektors ( ul.RessortNavigation>li>a::attr(href) ) extrahiert, danach wird für jede dieser URLs ein neuer HTTP-Request geschickt, und die Funktion parse_ressort_page als Callback aufgerufen.
Bei dem verwendeten Selektor ist anzumerken ist, dass der String ::attr(href), der dem CSS-Selektor angehängt ist, kein Standard CSS3-Selektor sondern spezifisch für Scrapy ist. Damit ist es möglich den Wert des href-Attributs wie in <a href="http://www.examplenewspaper.com/politik">Hyperlink</a> auszulesen. Dies ist ein entscheidender Unterschied zu XPath-Selektoren, bei denen dies standarmäßig möglich ist. Zwar wird CSS für viele Entwickler die gängigere Variante sein, allerdings ist XPath mächtiger wie in nachfolgenden Beispielen zu sehen ist.
Die Methode parse_ressort_page funktioniert nach demselben Prinzip wie parse_start_page, nur dass anstelle der Ressort-URLs nun die Artikel-URLs ausgelesen werden und parse_article_page als Callback-Funktion zugewiesen wird.
In parse_article_page werden dann schließlich die Inhalte der Zeitungsartikel ausgelesen (Methode get_article_data) und gespeichert (Methode save_local).
github:b2ad188977f9803410d252eb6125e0a2
Die Methode get_article_data selektiert und extrahiert zunächst alle Paragraphen und Überschriften der einzelnen Artikel, und säubert diese dann von allen störenden HTML-Tags (s. Funktion w3lib.html.remove_tags). Aus <p>Ich bin ein Paragraph</p> würde z.B. „Ich bin ein Paragraph“. Im Anschluss werden die Artikel jeweils in einem Python Dictionary gespeichert.
In unserem konkreten Fall machte es Sinn neben den reinen Artikel-Texten auch zusätzlich gewisse Metadaten zu den Zeitungsartikeln zu extrahieren, wie z.B. eine eindeutige Artikel ID, das Ressort, das Publikationsdatum, etc. Das Vorgehen ist hierbei sehr ähnlich zur Extraktion der Texte und wird hier deswegen nicht näher beschrieben.
Der Export der einzelnen extrahierten Artikel ist dann ganz einfach. Da wir unsere Artikel als Dictionaries speichern, bietet es sich an diese als JSON zu exportieren. Dies passiert mit unserer Methode save_local.
github:c2ec788cc991b085f518175a5d481abb
Ein heruntergeladener Artikel würde von der Struktur her dann z.B. so aussehen:
github:4cc7caf92269a856fd2eaa9c4005619f
So, das war es eigentlich schon fast. Wir brauchen unseren Spider nur noch zu starten, wie in der Methode run_spider gezeigt und unsere Zeitungsartikel landen als einzelne Dateien auf unserer Festplatte, bereit zur weiteren Verarbeitung. Man sieht schon wie komfortabel Web Scraping mit Scrapy ist: Scrapy abstrahiert für uns im Hintergrund natürlich eine Menge Arbeit, wie concurrent requests, retrying, etc., um die wir uns andernfalls Gedanken machen müssten.
github:e1ad425a2e895ef98e9904f3c155863a
Stay tuned
Wir haben hier ein einfaches Vorgehen gezeigt, das die grundsätzlichen Prinzipien und Schritte des Web Scrapings erklärt. Im Detail müssen je nach Anwendungsfall natürlich noch weitere Aspekte bedacht werden. So können z.B. unterschiedliche Artikeltypen eigene Strukturen haben, oder sich über mehrere Seiten erstrecken, usw.Da wir für unseren Uses Case eines Proofs of Concept eine Recommendation Engine für aktuelle Zeitungsartikel entwickelt haben, war es außerdem wichtig das Web Scraping nicht nur wie beschrieben einmalig sondern kontinuierlich in festgelegten Intervallen auszuführen. Dafür haben wir unsere Scraping Pipeline auf Amazon AWS mit einer serverless Architektur (AWS Lambda und DynamoDB) deployed.
Das war dann auch schon der erste Teil unserer Blogserie zum Thema Natural Language Processing mit Python. Wir haben gesehen wie einfach es ist mit Python bzw. Scrapy automatisiert aktuelle Artikel einer Tageszeitung zu extrahieren und für die weitere Verarbeitung zu speichern.
Im nächsten Teil werden wir uns damit befassen wie man Text-Daten so vorverarbeiten kann bzw. sogar muss, dass sie sich für verschiedene spannende Use Cases, wie z.B. Text Classification, Sentiment Analysis oder Recommendation eignen.
In diesem Sinne
Stay tuned!
Falls Du auch Lust hast Dich mit Themen wie NLP, Data science, Data pipelines, Cloud computing, Web Scraping oder Python zu beschäftigen schau doch einfach mal auf unsere Jobs. Wir freuen uns darauf Dich kennenzulernen.

